Батурин А.В., Молотков Л.И.
ОПЫТ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ БАЗЫ ДАННЫХ
SCIENCE CITATION INDEX В НАУКОМЕТРИЧЕСКИХ ЦЕЛЯХ*
| | Рассмотрены задачи наукометрического анализа сетей цитирования публикаций на основе использования машиночитаемой базы данных Science Citation Index (SCI). Описаны процедуры группирования цитированных источников, процедуры определения тематики выделенных кластеров источников по заглавиям цитирующих статей. Алгоритмы программно реализованы в Международном центре научной и технической информации. Представлены результаты экспериментальной обработки массива SCI объемом 84 тыс. описаний документов, содержащих около 1 млн. библиографических ссылок. Обсуждены вопросы дальнейшего развития методов и средств автоматизированной технологии наукометрического анализа. | | Ключевые слова: | наукометрия, кластерный анализ, машиночитаемая база данных Science Citation Index, алгоритмы, программное обеспечение, библиографические ссылки, сети цитирования, метод совместного цитирования |
|
ВВЕДЕНИЕ
Изучение состояния и закономерностей развития науки и техники путем анализа потоков научно-технической информации является одной из главных задач наукометрии. В последнее время интенсивное развитие получили наукометрические методы, основанные на анализе сетей цитирования публикаций [1, 2, 3]. Широкомасштабные наукометрические исследования с помощью этих методов стали возможны благодаря базе данных Science Citation Index (SCI), специфической особенностью которой является наличие в библиографических записях ссылок на цитируемые источники. База данных выпускается Институтом научной информации США в виде печатного издания и в машиночитаемом виде на магнитных лентах. Периодичность выпуска на магнитных лентах - 1 выпуск в неделю. Ежегодно в состав SCI вводится более 500 тыс. библиографических описаний документов приблизительно из 3800 важнейших журналов, издаваемых в мире по всем областям естественных наук, техники, технологии и медицины. При этом включается вся полезная информация, содержащаяся в журнале (статьи, редакционные сообщения, письма и т.п.).
Можно выделить три основных направления наукометрических исследований, проводимых на основе базы данных SCI.
1. Исследование внутренней структуры областей знания, выявление исторических особенностей и тенденций развития науки и техники [4, 5]. В основе этих исследований лежит один из методов анализа сетей цитирования - метод совместного цитирования двух публикаций (co-citation) [6, 7].
2. Формирование групп тематически связанных журналов [8, 9], оценка качества этих журналов и их взаимного влияния друг на друга, включая измерение факторов влияния (impact factor), факторов "быстрого {переход со стр.54 стр.55} реагирования" на данный журнал (immediacy index), коэффициентов самоцитирования и других библиометричеcких показателей [10, 11].
3. Получение оценок научного вклада отдельных ученых [12] и научной деятельности отдельных организаций и стран [13].
Эффективное и широкомасштабное решение указанных задач требует использования базы данных SCI в машиночитаемом виде в сочетании с соответствующим программным обеспечением.
В Международном центре научной и технической информации в рамках работ по проекту "Указатель научных ссылок" были разработаны алгоритмические и программные средства, обеспечивающие машинную обработку SCI. Работоспособность и функциональные возможности этих средств испытаны в ходе экспериментальных работ на массиве SCI объемом 84 тыс. описаний документов. В настоящей статье излагаются основные результаты выполненных работ, отражающие опыт МЦНТИ по автоматизированной обработке SCI. стр.55} реагирования" на данный журнал (immediacy index), коэффициентов самоцитирования и других библиометричеcких показателей [10, 11].
3. Получение оценок научного вклада отдельных ученых [12] и научной деятельности отдельных организаций и стран [13].
Эффективное и широкомасштабное решение указанных задач требует использования базы данных SCI в машиночитаемом виде в сочетании с соответствующим программным обеспечением.
В Международном центре научной и технической информации в рамках работ по проекту "Указатель научных ссылок" были разработаны алгоритмические и программные средства, обеспечивающие машинную обработку SCI. Работоспособность и функциональные возможности этих средств испытаны в ходе экспериментальных работ на массиве SCI объемом 84 тыс. описаний документов. В настоящей статье излагаются основные результаты выполненных работ, отражающие опыт МЦНТИ по автоматизированной обработке SCI.
СТРУКТУРА И СОСТАВ ФАЙЛОВ БАЗЫ ДАННЫХ SCI
Институт научной информации США выпускает машиночитаемую базу данных SCI в нескольких вариантах. МЦНТИ имел доступ к файлам, содержащим следующие основные библиографические данные:
-- идентификационный номер документа;
-- название журнала (полное и сокращенное 11-символьное);
-- том, номер выпуска, год выпуска журнала;
-- заглавие документа;
-- код вида документа (статья, редакционное сообщение, техническая заметка, письмо и др.);
-- фамилия и инициалы авторов документа;
-- место работы авторов;
-- библиографические ссылки (фамилия и инициалы первого автора цитированного документа, сокращенное 20-символьное название цитированного документа, том, номер первой страницы, две последние цифры года публикации). КЛАСТЕРНЫЙ АНАЛИЗ БИБЛИОГРАФИЧЕСКИХ ССЫЛОК
МЕТОД ГРУППИРОВАНИЯ ЦИТИРОВАННЫХ ДОКУМЕНТОВ
Библиографические ссылки, входящие в состав записей SCI,определяют цитируемые документы, которые могут являться элементами сети цитирования, если для этих элементов определить некоторую функцию связи. Одним из методов задания такой связи является метод совместного цитирования. Согласно этому методу два документа считаются связанными, если они были совместно процитированы хотя бы в одной публикации. Число публикаций, процитировавших данную пару документов, определяет силу этой связи.
Связь по совместному цитированию характеризуется тем, что она устанавливается через некоторое время после публикации, когда начинают появляться ссылки на данную работу. Связь является динамичной - сегодня связываются одни работы, а завтра они окажутся связанными с работами из другой предметной области и составят новую группу (кластер); прошлые научные публикации группируются с позиции текущего времени. Эти свойства связи позволяют использовать кластерный анализ библиографических ссылок на основе {стр.55стр.56}
 | | Рис.1 {стр.56}. Структура записей базы данных SCI |
метода совместного цитирования в наукометрии: жизнь кластеров цитируемых источников, их эволюция, видоизменение в известной мере отражают развитие науки.
АЛГОРИТМИЧЕСКОЕ И ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
ГРУППИРОВАНИЯ ЦИТИРОВАННЫХ ДОКУМЕНТОВ
Исходным алгоритмом группирования цитированных источников, который был программно реализован, являлся алгоритм Смолла и Гриффита [15]. В процессе реализации в этот алгоритм был внесен ряд изменений и дополнений. На рис.2 приведена блок-схема реализованного алгоритма группирования документов по их совместной цитируемости.
Из файлов базы данных выделяются библиографические ссылки с указанием идентификационного номера цитирующего документа, которые затем упорядочиваются по алфавиту. На следующем шаге выделяются высокоцитируемые источники, которые являются определяющими при дальнейшей аналитической обработке. Вместе с тем в ряде случаев оказалось полезным выделять не только высокоцитируемые источники, а некоторый слой ссылок путем введения ограничения на частоту цитирования сверху, то есть использовать послойную группировку с тем, чтобы при необходимости проанализировать связи и низкоцитируемых источников.
Далее выделенные ссылки сортируются по идентификационным номерам документов, для каждого цитирующего документа составляются пары совместно цитированных источников, которые затем упорядочиваются и объединяются с вычислением силы связи каждой пары.
Полученный набор пар ссылок определяет все связи в выделенном слое. В задачах практической обработки сети цитирования слабые связи, характеризующие случайные или неустоявшиеся связи, обусловленные недостатками аппарата цитирования [1], могут быть исключены введением порога по частоте совместного {стр.56стр.57} цитирования. Пары ссылок, имеющие частоту совместного цитирования ниже установленного порога, из дальнейшей обработки исключаются.
 | Рис.2 {стр.57}. Функциональная схема группирования документов
по принципу совместного цитирования |
Оставшиеся пары ссылок можно показать в виде матрицы (рис.3). Отметим, что полная информация о парах цитированных источников содержится в косоугольной матрице, например, выше диагонали. В то же время алгоритм полносвязывающего метода группирования для удобства реализации требует, чтобы вся матрица была заполнена данными, что достигается путем введения процедур реверса, слияния и упорядочивания пар ссылок. {стр.57стр.58}
Для примера рассмотрим процесс группирования элементов матрицы, показанной на рис.3.
 | | Рис.3 {стр.58}. Процесс группирования на основе матрицы связей |
Будем сканировать матрицу по строкам. Ссылка S1 связана с ссылками S4 и S8. Ссылка S4 - с S7 и S1, S8 - с S1. Ссылка S7, если бы не было инверсных пар, была бы последним элементом в группе. Наличие инверсных пар позволяет зафиксировать связь S7 с S2 и S9. Таким образом, в одну группу будут объединены ссылки S1, S4, S8, S7, S2, S9. Аналогичным образом в другую группу выделяются элементы S3, S5, S6, S10. Программно этот процесс реализован с использованием индексно-последовательного доступа к парам с общей частью ключа.
Вывод для каждого кластера запрограммирован в виде пронумерованной последовательности прямоугольников, содержащих библиографические ссылки. Выводится также таблица связей совместно цитируемых источников с указанием частот совместного цитирования f. Такая информация позволяет представить выделенные кластеры графически (рис.4).
АЛГОРИТМИЧЕСКОЕ И ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
ОПРЕДЕЛЕНИЯ ТЕМАТИКИ ВЫДЕЛЕННЫХ КЛАСТЕРОВ
Известно, что задача предметной идентификации групп цитированных источников является в наукометрии актуальной [15]. Для решения этой задачи был использован алгоритм, позволяющий дополнительно к кластеру цитированных документов получить кластер аналогичной структуры, каждый элемент которого {стр.58стр.60 (на стр.59 - рис.4)}
 | | Рис.4 {стр.59}. Пример графического изображения структуры кластера цитированных документов |
{стр.58стр.60 (на стр.59 - рис.4)} есть перечень часто встречающихся терминов из заглавий статей, цитирующих соответствующий источник (рис.5). Таким образом тематика групп цитированных источников определяется в терминах публикаций сегодняшнего дня.
Программная реализация алгоритма обеспечивает следующие логические операции (рис.6):-- выделение заглавий документов и их идентификационных номеров из базы данных;
-- селекцию заглавий цитирующих документов для заданного кластера цитированных источников;
-- подготовку указателя заглавий цитирующих документов для каждого кластера;
-- терминальную обработку заглавий цитирующих статей: заглавия статей выводятся на экран терминала, после чего пользователь помечает в них ключевые слова;
-- группирование помеченных ключевых слов и вывод высокочастотных терминов в виде кластера, аналогичного по структуре соответствующему кластеру цитированных источников.
ЭКСПЕРИМЕНТАЛЬНАЯ ОБРАБОТКА SCI ПО ГРУППИРОВАНИЮ
ЦИТИРОВАННЫХ ИСТОЧНИКОВ И ИХ ТЕМАТИЧЕСКОЙ ИДЕНТИФИКАЦИИ
Основная цель экспериментов заключалась в том, чтобы проверить работоспособность и функциональные возможности реализованных алгоритмов и программных средств кластерного анализа, показать формы представления выходных данных анализа и промоделировать способы последующей содержательной интерпретации этих данных. Эксперименты проводились на массиве SCI объемом 84 тыс. описаний документов, содержащих около 1 млн. библиографических ссылок.
В ходе проведения кластерного анализа пороговые значения частоты цитирования (n) и частоты совместного цитирования (f) варьировались в диапазоне от 2 до 5. В табл.1 представлены результаты группирования, полученные при n 5, f3.
Значения n5, f3 являются для экспериментального массива достаточно высокими: из массива в 84 тыс. документов этим условиям удовлетворяют 375 документов. В результате обработки эти высокоцитируемые документы группируются в 54 кластера. 5, f3.
Значения n5, f3 являются для экспериментального массива достаточно высокими: из массива в 84 тыс. документов этим условиям удовлетворяют 375 документов. В результате обработки эти высокоцитируемые документы группируются в 54 кластера.
| | | | Т а б л и ц а 1 | | |
 |
Размер
кластера | | Количество
кластеров | | Количество
документов |
|
| 2 | 28 | 56 |
| 3 | 7 | 21 |
| 4 | 6 | 24 |
| 5 | 1 | 5 |
| 6 | 2 | 12 |
| 7 | 4 | 28 |
| 8 | -- | -- |
| 9 | 1 | 9 |
| 10 | -- | -- |
| 11 | 2 | 22 |
| 17 | 1 | 17 |
| 33 | 1 | 33 |
| 148 | 1 | 148 |
| Всего | 54 | 375 |
|
|
В табл.2 приведены основные характеристики выделенных кластеров:-- количество документов, входящих в кластер;-- количество связей между документами кластера;-- коэффициент относительной плотности связей,определяемый как
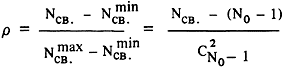 | , |
| где | | 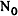 -- число документов в кластере, -- число документов в кластере, |
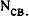 -- число связей, -- число связей, |
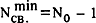 | -- | минимально возможное число связей, |
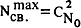 | -- | максимально возможное число связей ( 0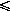 r1 ); r1 ); |
| -- название кластера. |
Названия кластеров определялись путем тематического анализа заглавий цитирующих статей. Наблюдается характерная взаимосвязь между степенью тематической специализации кластеров и значением коэффициента относительной плотности связей r: чем выше плотность связей между элементами кластера, тем более специфично и детально определена тематика этого кластера.
Например, кластер N 5, для которого r = 60%, относится к одному из специализированных направлений физики твердого тела - исследованию проводимости тонких металлических пленок. С другой стороны, кластер N 7 с низкой плотностью связей (r = 1,5%) охватывает широкий спектр исследований в области биомедицины. Детальное рассмотрение структуры кластера N 7 "Биомедицина" показывает, что в его основе лежит высокоцитируемая методическая статья О.Х.Лоури, опубликованная в 1951 г. в журнале "Journal of Biological Chemistry", в которой предложена модификация прежнего метода определения белка. Эта статья цитируется более ста раз и сильно связана практически со всеми остальными документами кластера, объединяя тем {стр.60стр.61} самым различные тематические направления исследований в области биомедицины в одну общетематическую группу. Для выделения отдельных тематических направлений целесообразно удалить из рассмотрения данную методическую работу. Это достигается путем введения ограничения на частоту цитирования документов сверху. В результате группирования ссылок базы данных при значениях частоты цитирования в диапазоне 5n50 кластер N 7 "Биомедицина" распался на 14 изолированных групп, каждая из которых характеризует отдельное тематическое направление исследований в области биомедицины: "Механизм действия холерного токсина" (группа из 13 документов), "Кинетическая модель синтеза белков" (9 документов), "Белковая структура рибосом" (9 документов) и др.
Т а б л и ц а 2
Номер
кластера | Количество
документов | Количество
связей | Относительная
плотность
связей | Название кластера |
| 1 | 7 | 7 | 7% | Рентгеновская кристаллография |
| 2 | 11 | 13 | 7% | Свойства жидкого гелия |
| 3 | 33 | 52 | 4% | Межзвездные системы и туманности |
| 5 | 6 | 11 | 60% | Проводимость тонких металлических пленок |
| 6 | 7 | 17 | 73% | Инсулино-индуцированная гипоглекимия |
| 7 | 148 | 295 | 1,5% | Биомедицина |
| 9 | 7 | 8 | 13% | Трансформация структуры генов |
| 16 | 11 | 17 | 16% | Спектры излучения квазаров |
| 17 | 17 | 59 | 36% | Вирус Эпштейна-барра |
| 24 | 9 | 20 | 43% | Исследование структуры мембран
методами ядерной физики |
| 32 | 7 | 11 | 33% | Инфаркт миокарда |
| 34 | 6 | 11 | 60% | Активаторы опухолей |
П р и м е ч а н и е. Приведены наиболее крупные по размеру кластеры (количестводокументов в кластере 6).
На рис.7 в качестве примера показана структура одного из кластеров, сформированных при значениях n5, f3, - кластера N 2 "Свойства жидкого гелия", а на рис.8 - тематический образ этого кластера. Тематический образ получен с помощью программ частотной обработки слов заглавий статей, цитирующих документы данного кластера. Так, документ N 4 кластера (Wheatley JC, Rev. Mod. Phys., vol.47, p.414, 1973) цитирован в 14 статьях, в заглавиях которых слово superfluid встречается 8 раз, слово He-3 - 5 раз, слово liquid-He-3 - 3 раза и т.д. Видно, что документы кластера, имеющие близкие тематические образы, соединены более сильными связями (например, документы N 7 и N 11, N 7 и N 10).
Анализируя результаты работы алгоритма автоматического определения тематики кластеров, следует заметить, что использование для этой цели только одних заглавий цитирующих документов, на наш взгляд, представляется недостаточным. Для полноты тематической интерпретации необходимо привлекать также заглавия цитированных документов кластера. Хотя заглавия цитирующих документов отсутствуют в записях библиографических ссылок SCI, в принципе они могут быть найдены в ретрофайлах базы данных или в коммулятивных печатных указателях SCI "Source Index" за соответствующий год. {стр.61стр.63 (стр.62 - рис.5)}
 | | Рис.5 {стр.62}. Тематический образ кластера, представленного на рис.4 |
{стр.61стр.63} С помощью библиографических описаний цитирующих и цитированных документов возможна последующая содержательная интерпретация рассматриваемых кластеров. В частности, в выделенной предметной области "Свойства жидкого гелия" прослеживаются 3 направления исследований:I -- исследование свойств жидкого гелия с помощью ЯМР-методов (ключевые авторы: Aalto MI, Ahonen AI, Legget AJ);
II -- эксперименты по измерению теплоемкости сверхтекучего гелия (ключевые авторы: Alvesalo TA, Wheatley JC, Halperin WP);
III -- исследование распространения колебаний и волн в сверхтекучем гелии (ключевые авторы: Avenel Q, Giannetta RW, Koch VE, Mast DB).
Библиографические описания документов содержат важную информацию о наиболее активных авторах и организациях, проводящих исследования в данной области. В рассматриваемом случае такими организациями являются: Laboratory of Atomic and Solid State Physics and Materials Science Center; Cornell University (USA) и Low Temperature Laboratory; Helsinki University of Technology (Finland).
 | Рис.6 {стр.63}. Функциональная схема определения тематических образов
кластеров цитированных документов |
Говоря о способах представления выходных результатов анализа, отметим, что в настоящее время заключительный этап этой процедуры - этап изображения кластеров в виде графов - производится вручную на основе {стр.63стр.64} табличных значений сил связи совместного цитирования пар документов. Учитывая, что, как правило, требуется изобразить большое число кластеров (примерно несколько десятков), имеющих в большинстве случаев сложную сеть связей между цитированными документами, возникает необходимость автоматизации - процедуры графического построения структуры кластеров.
 | | Рис.7 {стр.64}. Кластер N 2 "Свойства жидкого гелия" |
 | | Рис.8 {стр.64}. Тематический образ кластера N 2 "Свойства жидкого гелия" |
В основу этой процедуры может быть положен принцип, согласно которому расстояние между координатами цитированных документов обратно пропорционально частоте их совместного цитирования [16]. Чем сильнее связаны документы, тем ближе друг к другу они будут расположены. Такое изображение сетей цитирования существенно облегчит зрительное восприятие структуры кластеров их последующую наукометрическую трактовку.
В ходе экспериментальных работ была рассмотрена возможность проведения кластерного анализа предварительно сформированных массивов данных, относящихся к определенным предметным областям науки. Необходимость предварительного формирования таких массивов обусловлена наличием ограничений на объем внешней памяти, используемой программными модулями. Так, для дискового пакета емкостью 29 Мбайт количество группируемых элементов ограничивается примерно 2 тыс. {стр.64стр.65}
Формирование тематических массивов с целью сокращения количества группируемых ссылок может быть осуществлено путем выделения групп журналов, относящихся к одной предметной области.
| | | | Т а б л и ц а 3 | | |
|
Размер
кластера | | Количество
кластеров | | Количество
кластеров |
|
| 2 | 88 | 176 |
| 3 | 34 | 102 |
| 4 | 17 | 68 |
| 5 | 9 | 45 |
| 6 | 4 | 24 |
| 7 | 5 | 35 |
| 8 | 5 | 40 |
| 9 | 1 | 9 |
| 10 | | |
| 11 | | |
| 12 | 2 | 24 |
| 13 | 1 | 13 |
| 14 | 2 | 28 |
| 15 | 1 | 15 |
| 19 | 1 | 19 |
| 21 | 1 | 21 |
| 23 | 1 | 23 |
| 29 | 1 | 29 |
| 67 | 1 | 67 |
|
| Всего | 174 | 738 |
|
|
Такая тематическая фильтрация журналов может быть проведена как вручную путем экспертной оценки и отнесения журнала к данной предметной области, так и автоматически - на основе использования алгоритмов взаимного цитирования журналов.
В МЦНТИ реализован метод автоматического группирования журналов по их взаимному цитированию. При проведении экспериментальных работ с помощью этого метода было сформировано около 30 различных тематически связанных групп журналов. Среди них - группы журналов по физике, математике, астрофизике, биохимии и другие.
Алгоритм кластеризации на основе принципа совместного цитирования был применен к массивам статей, опубликованных в журналах, относящимся к двум предметным областям: физике и математике. В табл.3 в качестве примера приведены результаты кластеризации массива журнальных статей по физике, полученные при значениях n2, f2.
В общей сложности сформировано 174 кластера. Из них 86 - состоят более чем из трех цитированных документов. В состав 20 из этих 86 кластеров входят цитированные документы советских авторов. Характеристики этих кластеров приведены в табл.4. Кластеры сгруппированы по основным областям физики: физики полупроводников; физики металлов и диэлектриков; оптики и спектроскопии; физики элементарных частиц; физики низких температур. В пределах каждой области выделены ключевые направления исследований, в основе которых лежат работы советских авторов.
ЗАКЛЮЧЕНИЕ
Разработанные алгоритмические и программные средства кластерного анализа SCI обеспечивают:-- группирование документов на основе принципа совместного цитирования;
-- определение тематики выделенных кластеров на основе терминов заглавий цитирующих статей;
-- тематическую фильтрацию цитирующих статей на основе формирования групп научно-технических журналов;
-- послойную группировку цитированных источников;
-- выделение кластера по одному элементу, входящему в этот кластер.
В ходе экспериментальной проверки разработанных средств на реальном массиве SCI, содержащем около 1 млн. библиографических ссылок, подтверждена работоспособность этих средств и продемонстрированы их функциональные возможности.
Результаты эксперимента дают возможность сформулировать ряд направлений по дальнейшему развитию и совершенствованию алгоритмов и программных средств кластерного анализа. Наиболее актуальными из них являются:-- разработка и реализация алгоритмов группирования, учитывающих специфические особенности структуры связей в сетях цитирования (количество связей, длину пути между элементами сети и т.д.);
-- разработка новых методов автоматизированного определения тематики кластеров;
-- разработка средств геометрического моделирования кластеров в автоматическом режиме с возможностью отображения на терминальных устройствах с переменной степенью детализации связанных структур.
Работы в этих направлениях позволят расширить функциональные возможности имеющихся программных средств и существенно повысить их эффективность для решения наукометрических задач на основе базы данных SCI. {стр.65стр.66}
Т а б л и ц а 4
Номер
кластера | Количество
документов | Название кластера |
| 28 | 7 | Многоэкситонные комплексы в полупроводниках |  |
| 38 | 4 | Гетеропереходы в полупроводниках |
| 44 | 6 | Проводимость полупроводников в скрещенных электромагнитных
полях |
| 46 | 4 | Джозефсоновские переходы |
| 47 | 4 | Электронно-дырочная жидкость на поверхности германия |
| 153 | 3 | Диффузия ионизованных примесей в полупроводниках |
| 14 | 12 | Теория диэлектриков |  |
| 76 | 4 | Антиферромагнитные цепи |
| 101 | 4 | Свойства квазиодномерных сред |
| 108 | 3 | Теория проводимости металлов |
| 117 | 4 | Релаксация зарядов в поверхностных слоях |
| 120 | 6 | Электронная структура никелевых сплавов |
| 15 | 4 | Люминесценция полимеров |  |
| 16 | 4 | Комбинационное рассеяние излучения |
| 45 | 3 | Параметрические усилители излучения |
| 56 | 3 | Образование протонов при неупругих столкновениях ядер легких
элементов |  |
| 58 | 21 | Законы симметрии при ядерных взаимодействиях |
| 104 | 8 | Образование и рассеяние гравитонов |
| 26 | 8 | Зарождение вихрей в жидком гелии |  |
| 105 | 3 | Деформация поверхности жидкого гелия |
|
| Л И Т Е Р А Т У Р А |
| [1] | | Добров Г.М., Коренной А.А. Наука: информация и управление. - М.: Сов. радио, 1974. |
| [2] | | Маршакова И.В. Сети цитирования: информационные модели системы научных публикаций. - Обзоры по электронной технике. Серия 9 "Экономика и системы управления". М., ЦНИИ "Электроника", 1981, вып.1(760). {стр.66стр.67} |
| [3] | | Small H.G. The relationship of information science to the social sciences; a co-citation analysis. - Information Processing & Management, 1981, vol.17, p.39-50. |
| [4] | | Small H.G., Griffith B.C. The structure of scientific literature, I: Identifying and Graphing Specialities. - Science Studies, vol.4, p.17-40. |
| [5] | | Griffith B.C., Small H.G., Stonehill J.A., Dey S. The structure of scientific literature, II: Towards a macro- and micro-structure for science. - Science studies, 1974, vol. p.339-365. |
| [6] | | Маршакова И.В. Система связей между документами, построенная на основе ссылок. - НТИ, сер.2, 1973, N 6, с.3-8. |
| [7] | | Small H.G. Co-citation in the scientific literature a new measure of the relationship between two documents. - J. Amer. Soc. Inform. Sci., 1973, vol.24, N 4, p.265-269. |
| [8] | | Carpenter M.P., Narin F. Clustering of scientific journals. - J. Amer. Soc. Inform. Sci., 1973, vol.24, p.425-436. |
| [9] | | Servi P.N., Griffith B.C. A method for partitioning the journal literature. - J. Amer. Soc. Inform. Sci., 1980, vol.31, N 1, p.36-40. |
| [10] | | Garfield E. What scientific journals can tell us about scientific journals. - IEEE Transactions Professional Communication, 1973, vol.PC-16, N 4, p.200-202. |
| [11] | | Computer Horizons, Inc. Subject classification and influence weights for 2300 journals. Final task report for the period 1/1/74 to 12/31/74, Contract NSF-C627, June 30, 1975. |
| [12] | | Garfield E. Citation measure of the influence of Robert K. Merton. - Trans. of the New York Acad. of Sciences, ser.II, 1980, vol.39, p.61-74. |
| [13] | | Braun T., Bujdoso E., Ruff I. A tudomany mint a meres targya. Tudomanymetriai Kutatas Magyarorszagon. - Budapest: Magyar Tudomanyos Akademia Konyvtara, 1981. |
| [14] | | Батурин А.В., Горностаев Ю.М. Система комплексной идентификации файлов - СКИФ. В 3-х ч. - Методические материалы и документация по пакетам прикладных программ. М.: МЦНТИ, 1980, вып.6. |
| [15] | | Garfield E. Citation Indexing - its theory and application in science, technology and humanities. - N.Y., 1979, p.98. |
| [16] | | Small H., Greenlee E. Citation context analysis of a cocitation cluster: recombinant - DNA. - Scientometrics, 1980, vol.2, N 4, p.277-301. |
| | * | Опубликовано в сборнике: Проблемы информационных систем / Международный центр научной и технической информации, М., 1983, N 2, с.54-67, 4 табл., 8 рис. Библиогр.: с.66-67 (16 назв.) |
Документ изменен: Wed Feb 27 14:54:50 2019. Размер: 71,178 bytes.
Посещение N 8193 с 17.09.1998
|